pimmimade by the médialab
tool to study image copying in a corpus
Tools – Code
Nicolas Hervé, Béatrice Mazoyer
PIMMI is a software that performs visual mining in a corpus of images. Its main objective is to find all copies, total or partial, in large volumes of images and to group them together. Our initial goal is to study the reuse of images on social networks (typically, our first use is the propagation of memes on Twitter). However, we believe that its use can be much wider and that it can be easily adapted for other studies. The main features of PIMMI are therefore :
- ability to process large image corpora, up to several millions files
- be robust to some modifications of the images, typical of their reuse on social networks (crop, zoom, composition, addition of text, ...)
- be flexible enough to adapt to different use cases (mainly the nature and volume of the image corpora)
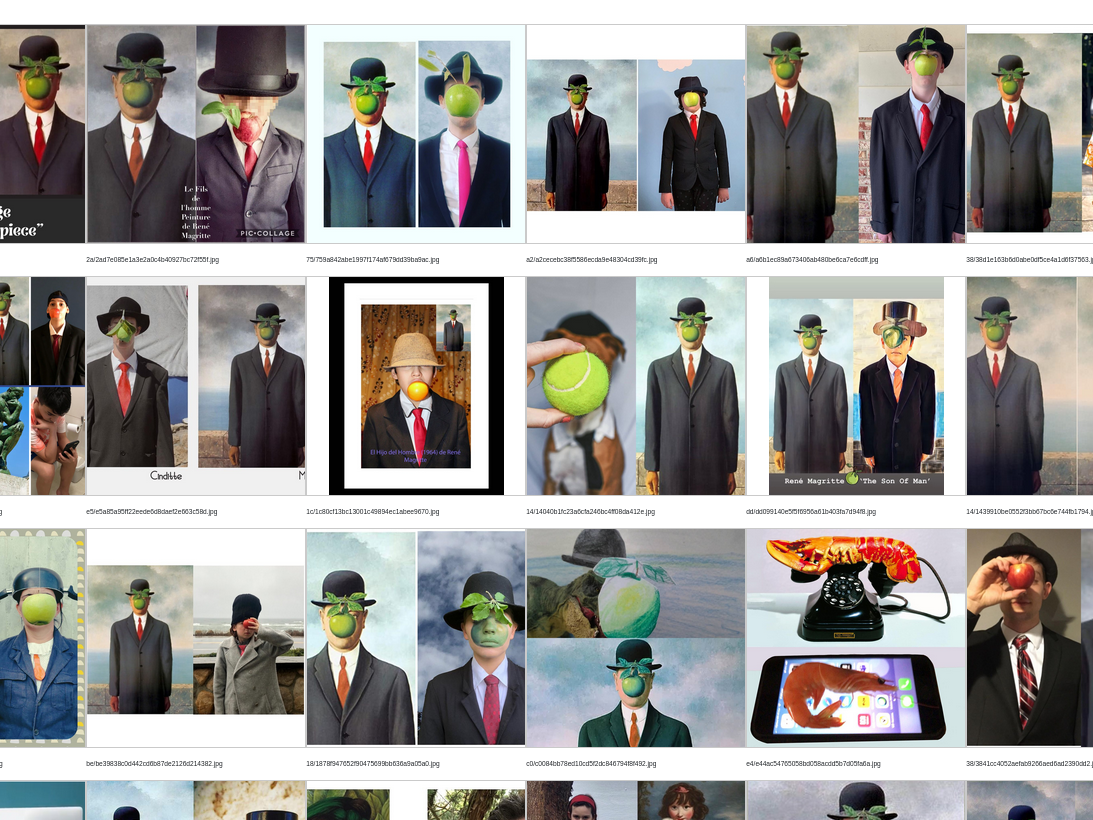
PIMMI is currently only focused on visual mining and therefore does not manage metadata related to images. The latter are specific to each study and are therefore outside our scope. Thus, a study using PIMMI will generally be broken down into several steps:
- constitution of a corpus of images (jpg and/or png files) and their metadata
- choice of PIMMI parameters according to the criteria of the corpus
- indexing the images with PIMMI and obtaining clusters of reused images
- exploitation of the clusters by combining them with the descriptive metadata of the images
PIMMI relies on existing technologies and integrates them into a simple data pipeline:
- Use well-established local image descriptors (Scale Invariant Feature Transform: SIFT) to represent images as sets of keypoints. Geometric consistency verification is also used. (OpenCV implementation for both).
- To adapt to large volumes of images, it relies on a well known vectors indexing library that provides some of the most efficient algorithms implementations (FAISS) to query the database of keypoints.
- Similar images are grouped together using standard community detection algorithms on the graph of similarities.
PIMMI is a library developed in Python, which can be used through a command line interface. It is multithreaded. A rudimentary web interface to visualize the results is also provided, but more as an example than for intensive use (Pimmi-ui).
The development of this software is still in progress : we warmly welcome beta-testers, feedback, proposals for new features and even pull requests !
exploration, visualization and curation
developers
experimental
2022