pimmifait par le médialab
outil permettant d'étudier les copies d'images dans un corpus
Outils – Code
Nicolas Hervé, Béatrice Mazoyer
PIMMI est un logiciel de fouille visuelle dans des corpus d'images. Sa fonction principale est de détecter les copies d'images, totales ou partielles, au sein de grands corpus, et de rassembler entre elles les images qui sont des copies les unes des autres. Notre objectif initial est d'étudier la réutilisation d'images sur les réseaux sociaux (Notre premier cas d'usage est la propagation de mèmes sur Twitter). Cependant, l'outil peut être facilement adapté à d’autres cas d'étude.
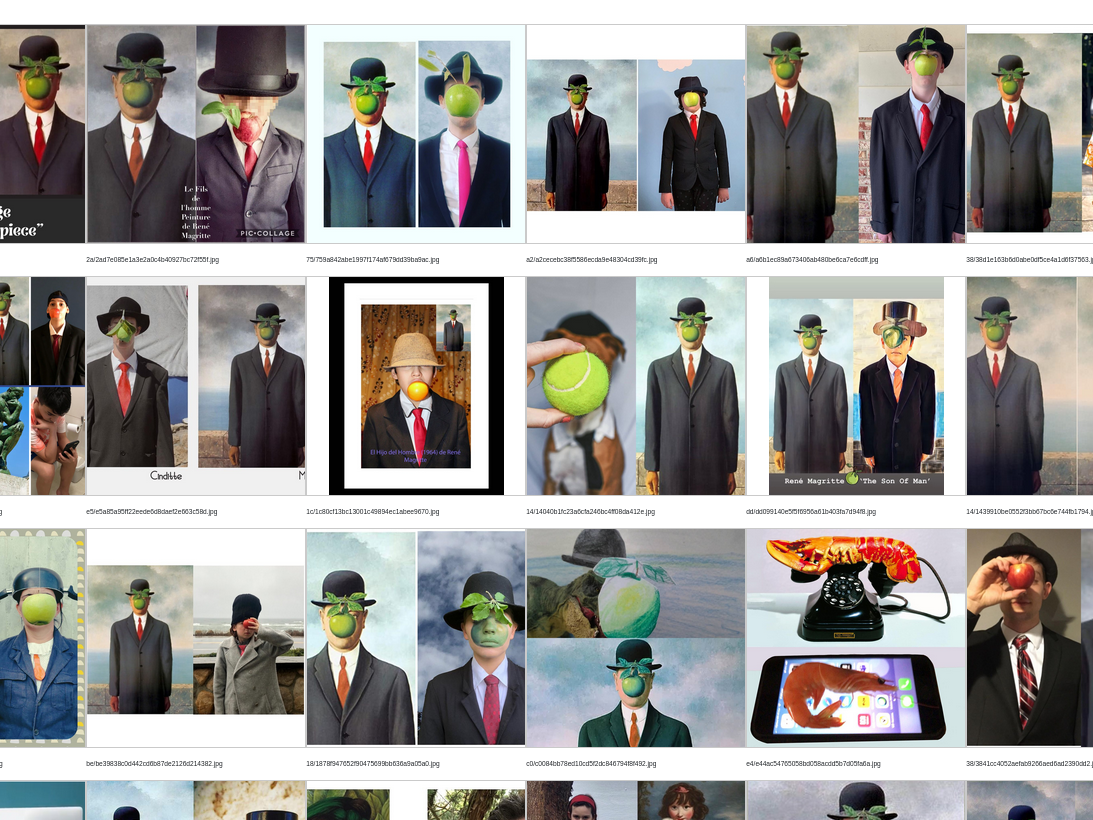
Les principaux atouts de l'outil sont les suivants :
- il permet de traiter des corpus d'images volumineux, jusqu'à plusieurs millions de fichiers
- il peut gérer certaines modifications d'images (recadrage, zoom, composition, ajout de texte, …) , typiques de leur réutilisation sur les réseaux sociaux
- il est paramétrable, pour s'adapter à différents types de corpus d'images et différentes tailles de jeux de données.
PIMMI se concentre actuellement uniquement sur le visual mining et ne gère donc pas les métadonnées liées aux images. Une étude utilisant PIMMI se décomposera généralement donc en plusieurs étapes :
- constitution d'un corpus d'images (fichiers jpg et/ou png) et de leurs métadonnées
- choix des paramètres PIMMI selon les critères du corpus
- indexation des images et création des clusters de copies d'images
- exploitation des clusters en les combinant avec les métadonnées descriptives des images.
Une interface web rudimentaire pour visualiser les résultats est également fournie, davantage à titre d'exemple que pour une utilisation intensive (pimmi-ui). Le développement de ce logiciel est toujours en cours : nous serions ravis d'avoir d'autres bêta-testeurs et nous sommes ouverts aux propositions de nouvelles fonctionnalités.
exploration, visualisation et curation
développeur.e.s
expérimental
2022