Une cartographie Web de l'écosystème IA en France
Qui sont les acteurs de l’écosystème IA français ? Quelles relations entretiennent-ils sur le Web ?
Chronique
Cette cartographie, sans prétendre à l’exhaustivité, tente de rendre compte de la composition et de la structure relationnelle des différents acteurs de l’IA en France sur le Web. Elle laisse apercevoir une segmentation entre plusieurs communautés d’acteurs majeures que sont les acteurs économiques (startups, incubateurs, etc.), les laboratoires et équipes de recherche en intelligence artificielle, ainsi que les communautés de développeurs qui se retrouvent autour d'événements (meetup) et les repository (Github) qui dessinent un réseau socio-technique d’acteurs variés (code logiciel, page de développeurs, de projet, d’équipe ou d’entreprise) interconnectés entre eux.
Un écosystème Web fragmenté par types d'activités
L'algorithme de modularité détecte sur le graphe complet quatre clusters ayant des caractéristiques variées tant du point de vue des types d'acteurs qui les composent que de leurs propriétés structurales (diamètre, densité, degré moyen). Ces quatre sous-ensembles se distinguent tout d'abord car ils dessinent les environnements au sein desquels l'intelligence artificielle se développe en France, à savoir, le milieu économique des startups (cluster vert, 37,6% du réseau), le milieu de la recherche scientifique (cluster violet, 31,5% du réseau), les communautés de développeurs (cluster orange, 5,5% du réseau) et de façon plus surprenante le réseau des pages de repository (Github) qui s'apparente à un réseau socio-technique mélangeant code informatique, page de projet et page de développeurs ou d’entreprises (cluster rose 25,4% du réseau).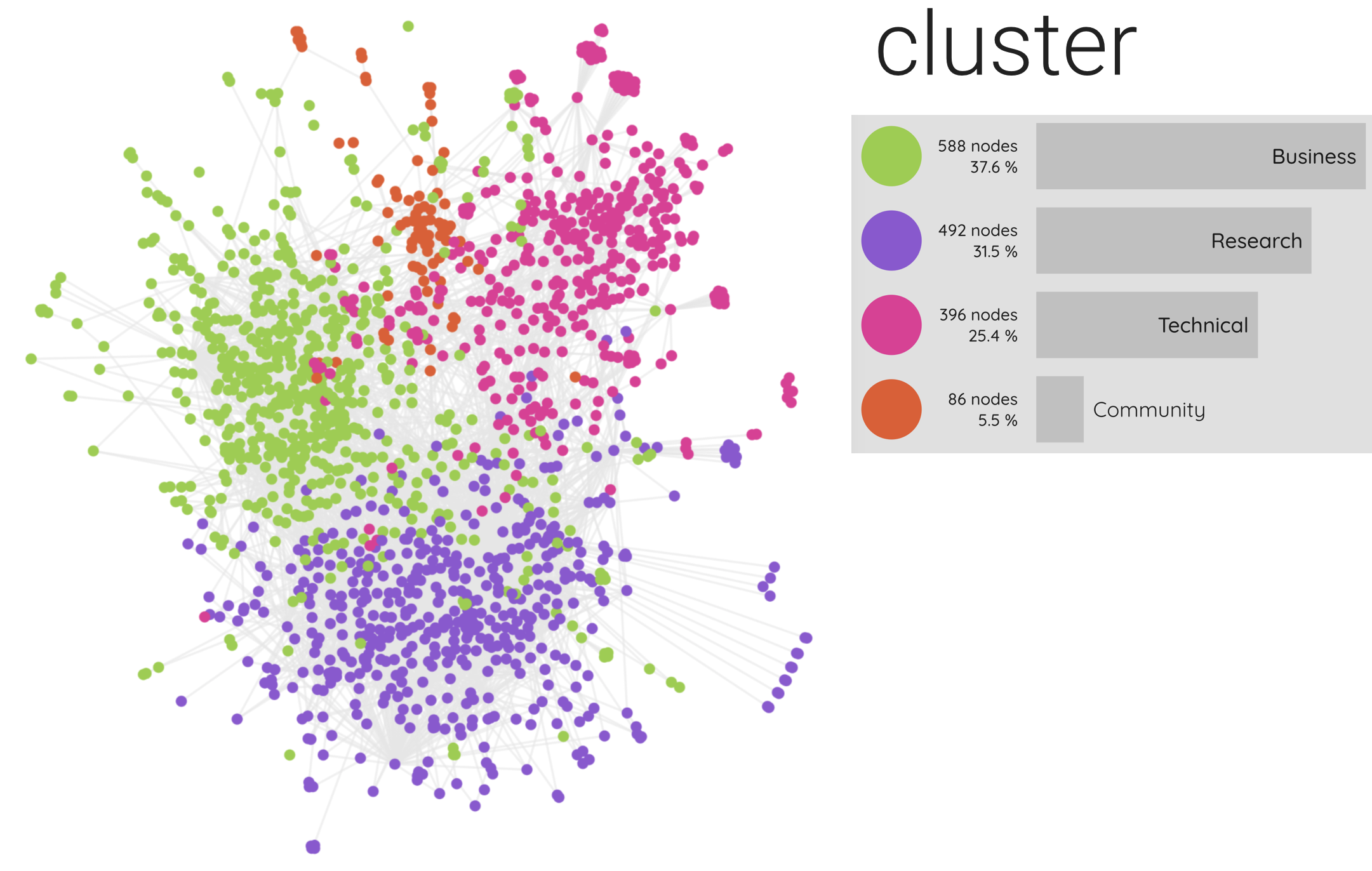
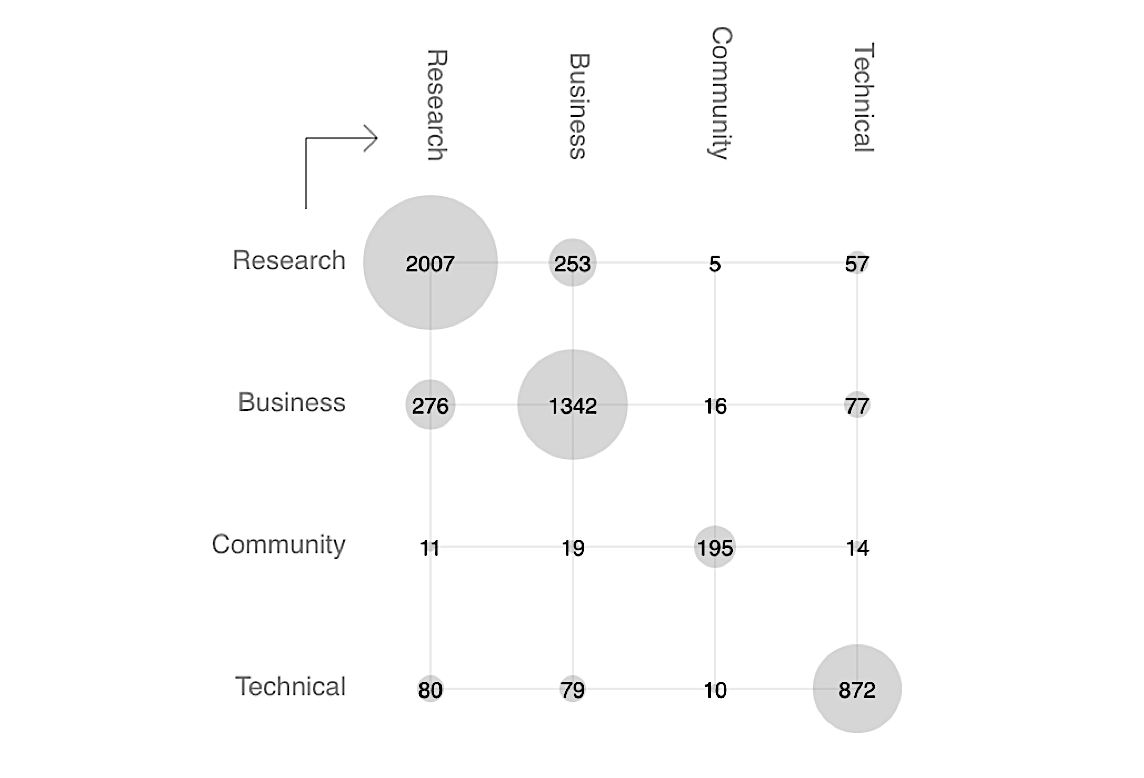
On observe une séparation assez claire sur le plan visuel entre ces différents clusters sur le graphe qui occupent chacun un espace qui leur est propre. Pourtant il existe de nombreux liens entre ces différents sous-ensembles mais leurs connexions (en termes de liens hypertextes) sont plus denses à l'intérieur de chaque composante qu'entre elles.
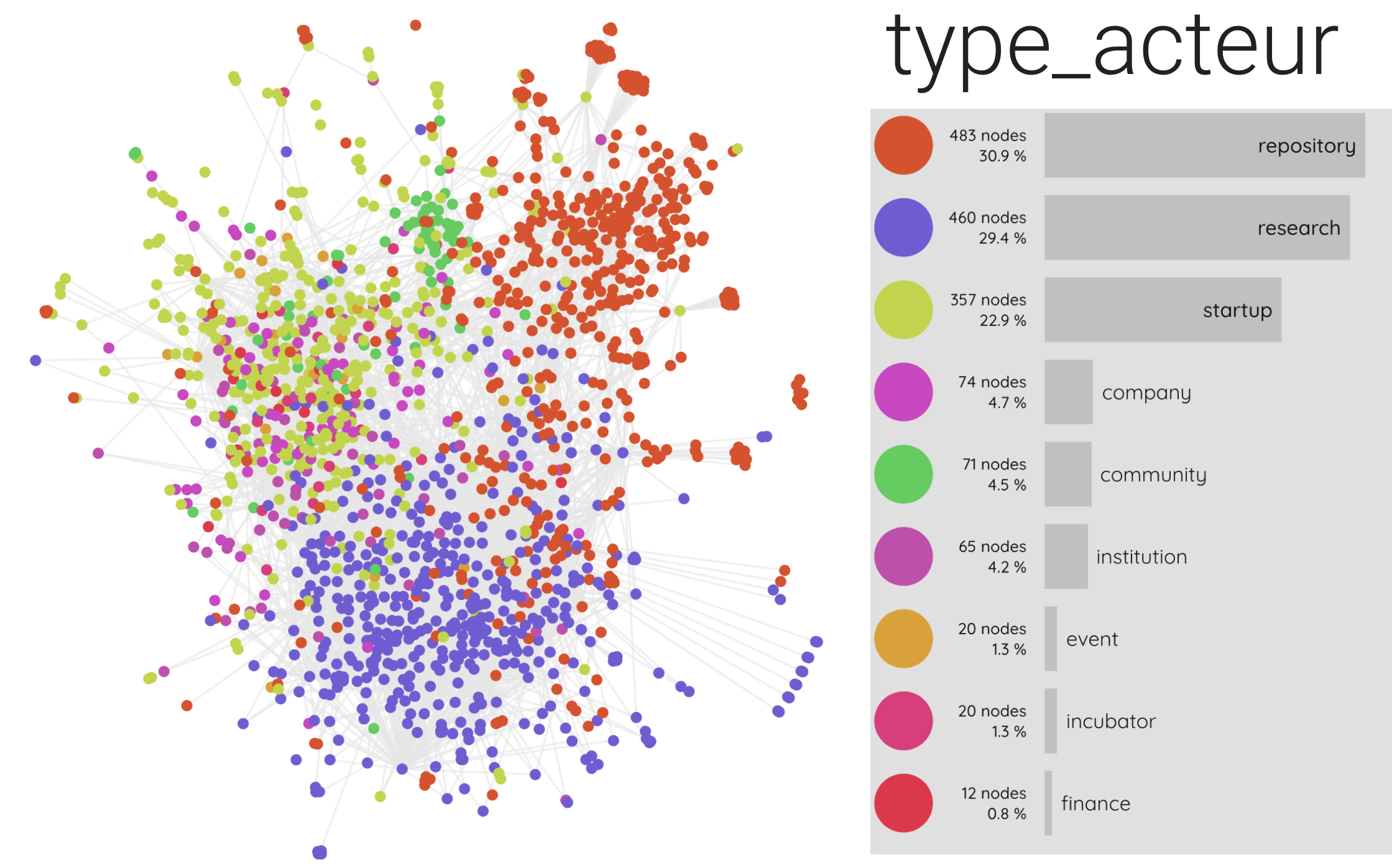
Il existe un grande variété des types d'acteurs au sein du réseau dont la répartition dans l'espace topologique permet d’interpréter et de différencier assez facilement les clusters révélés par l'algorithme de modularité. Le réseau complet est composé prioritairement d'entités web qui sont des repository (31% des entités web) et d'entités web liées à la recherche (29,4% des entités web), enfin des startups (22,0% des entités web). Il existe également d'autres acteurs moins représentés que sont les grandes entreprises françaises et internationales (ayant une activité en France) dans différents domaines (transports, santé, énergie, télécoms, technologies, etc.), les institutions (administrations, collectivités territoriales, etc.) ainsi que les communautés de développeurs qui organisent des rencontres et échanges (meetup), toutes représentent entre 4% et 5% des entités web du réseau. Enfin trois types d'acteurs que sont les incubateurs, les événements (conférences, concours de startup), ainsi que les organismes de financement représentent chacun autour de 1% des entités du réseau (détail des catégories d'acteurs par cluster).
Par ailleurs, il faut noter que chacun des sous-ensembles connaît en son sein une plus ou moins forte hétérogénéité (par types d'acteurs ou par territoires) qui exige une exploration plus fine de chacun des clusters.
Un réseau de soutien aux startups riche et diversifié
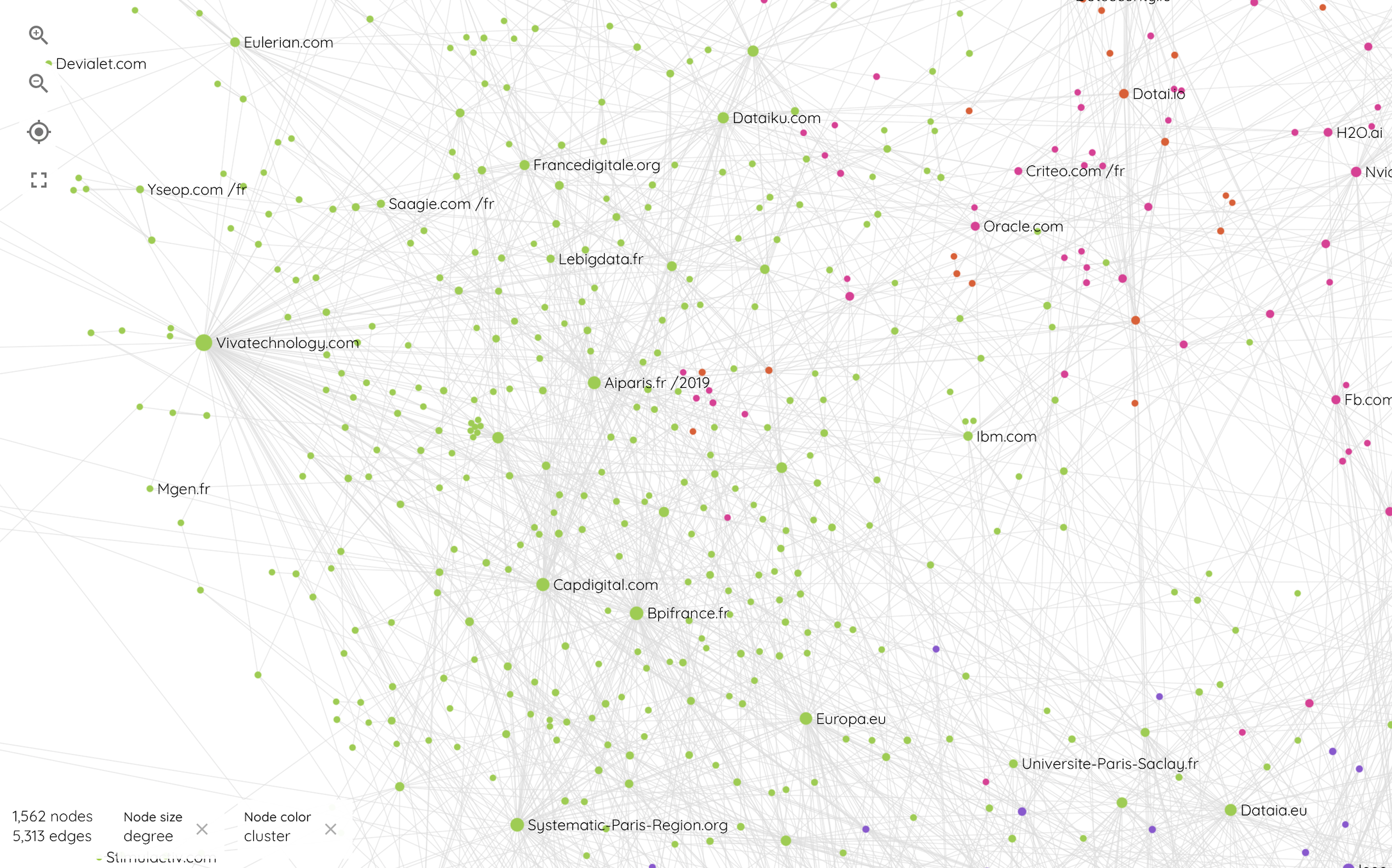
Moins dense et plus étendu que les clusters de la recherche ou des communautés de développeurs, le cluster Business se distingue par la grande hétérogénéité des acteurs qui le composent. S'il est majoritairement composé de startups (46,8%) il est également composé d'une plus grande concentration de grandes entreprises (9,7%) et d'institutions (8,2%), soit deux fois plus que sur l'ensemble du réseau. Les incubateurs, événements et financeurs y sont également deux à trois fois plus représentés que dans du réseau complet. On constate également la présence d'entités web liées à la recherche (14,3%) ou des repository (10,2%) qui, bien que sous représentées, composent une part significative du cluster. S'il est difficile de comprendre la structure interne de ce cluster, on s’aperçoit à l'exploration du graphe que des associations en termes de proximité territoriale, de domaine d'application et de financement tendent à connecter certains acteurs entre eux mais cette hypothèse nécessiterait un analyse plus approfondie de cette partie du réseau. Certains acteurs comme des événements dans le domaine des technologies (Vivatechnology, ParisIA), des institutions (CNIL, Europa) ou encore des organismes de soutien et de promotion (Capdigital, Systematic, FrenchTech) participent, du fait de leur centralité dans le réseau d'acteurs, à interconnecter l'ensemble des entités de ce cluster.
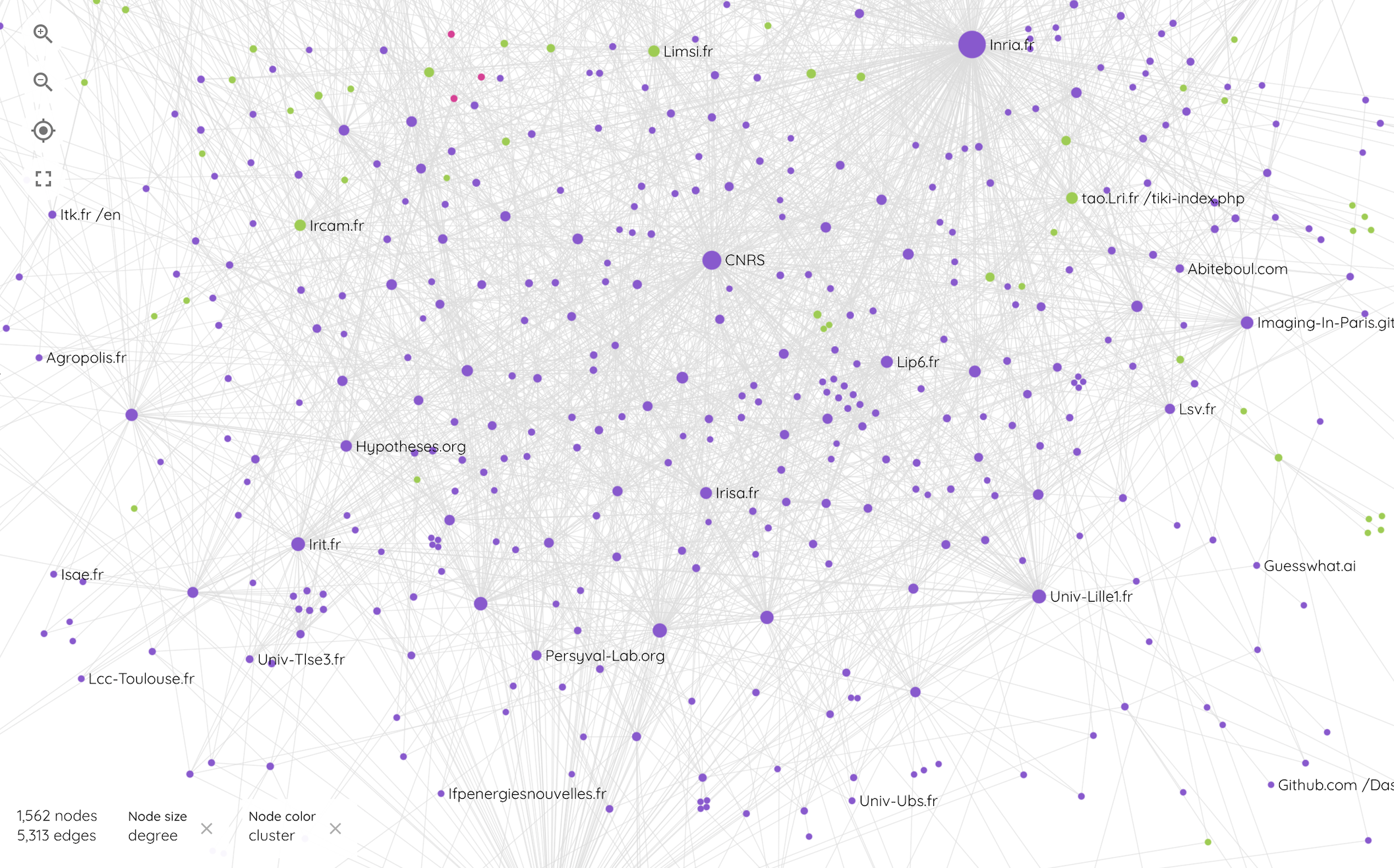
Le réseau dense de la recherche en intelligence artificielle
Le cluster recherche est le plus homogène du point de vue des acteurs qui le composent car il compte 72,8 % d'entités web associées à la recherche (laboratoire, projets de recherche, université, etc.). Il est également deux fois plus dense que les clusters business et technique et moins étendu en termes de diamètre. Les deux entités majeures qui tendent à agréger ce sous-ensemble sont assez logiquement l'INRIA et le CNRS. Sans que la structure interne soit facilement interprétable, on observe parfois des logiques territoriales qui tendent à structurer le réseau, c'est le cas par exemple, en bas à gauche du cluster, d'un sous-ensemble d'entités recherche localisées à Toulouse. Pourtant d'autres laboratoires ou projets de recherche semblent jouer également un rôle structurant dans cette partie du réseau. Ce cluster compte seulement 4% de startups mais 18,3 % d'entités identifiées comme des repository, formant souvent des petits îlots connectés autour de projets de recherche.
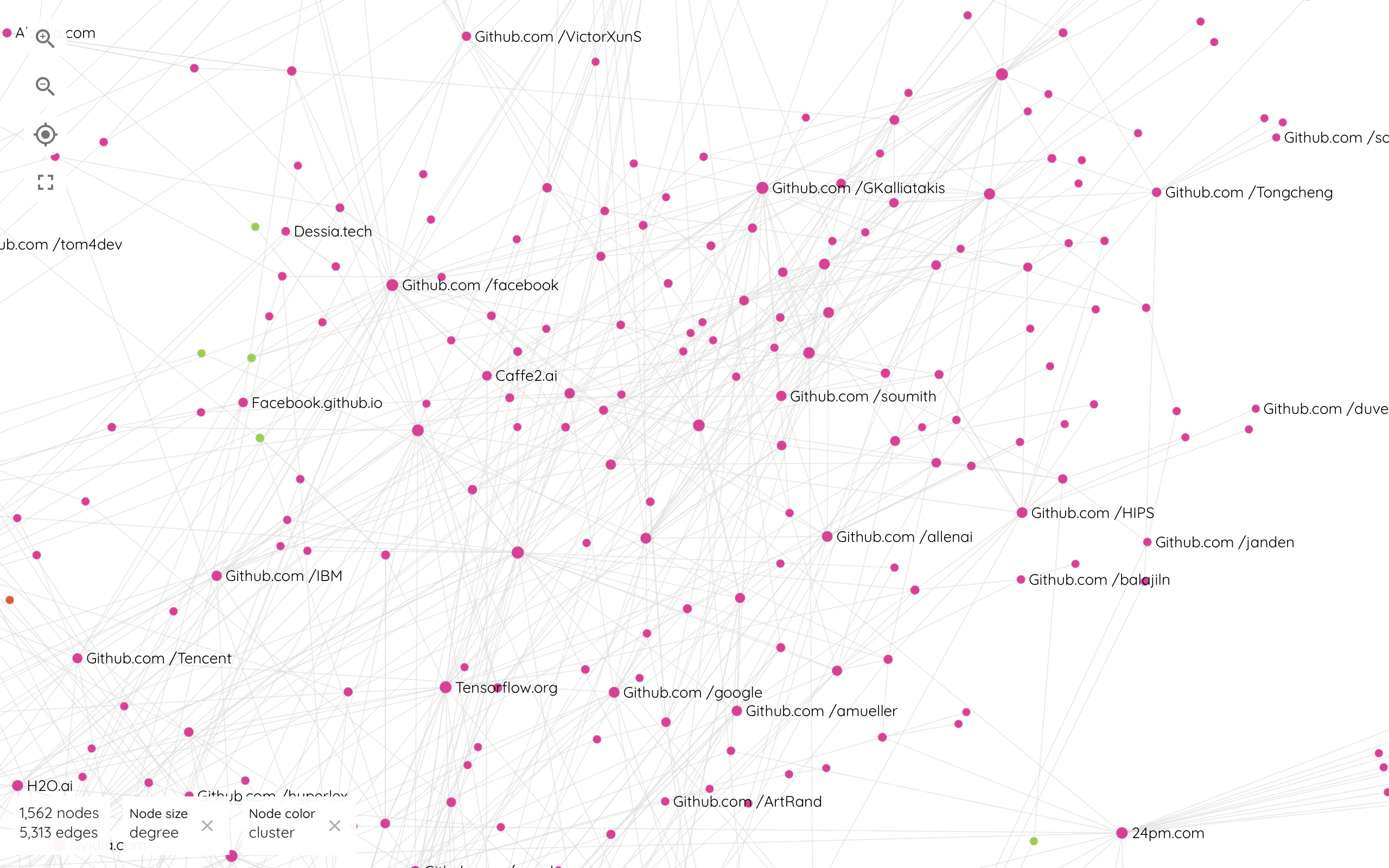
Les usages multiples des "repository"
La troisième composante est constituée à 79,6% de repository du site Github mais également de startups (10,2%), d'entités liées à la recherche (4,7%) et de grandes entreprises dans le secteur des technologies, telles que Uber, Nvidia ou encore Oracle. Etant donné la prépondérance de la web entité Github au moment du crawl des données, le choix méthodologique a été fait de séparer cette entité en un réseau d'entités plus fines qui dessinent ce sous-ensemble du graphe. Ce choix se justifie par la nature diversifié de ces acteurs. Ce cluster forme une composante technique de l'écosystème dans laquelle se lient des briques d'outils à un ensemble hétérogènes d'acteurs tels que des développeurs, des laboratoires ou projets de recherche ou encore des entreprises. D'autres entités techniques viennent se connecter dans ce réseau, telles que des forges de logiciels (Sourceforge), des concours de développement (Kaggle) ou encore des sites de logiciels open source (Tensor Flow, Scikit). Par ailleurs, il est intéressant de noter que si les entités étiquetées comme repository se concentrent essentiellement dans cette partie du réseau, elles représentent également les acteurs les plus distribués à l'échelle de l'ensemble du réseau et viennent se connecter à une multitude d'acteurs dans différentes régions du graphe.
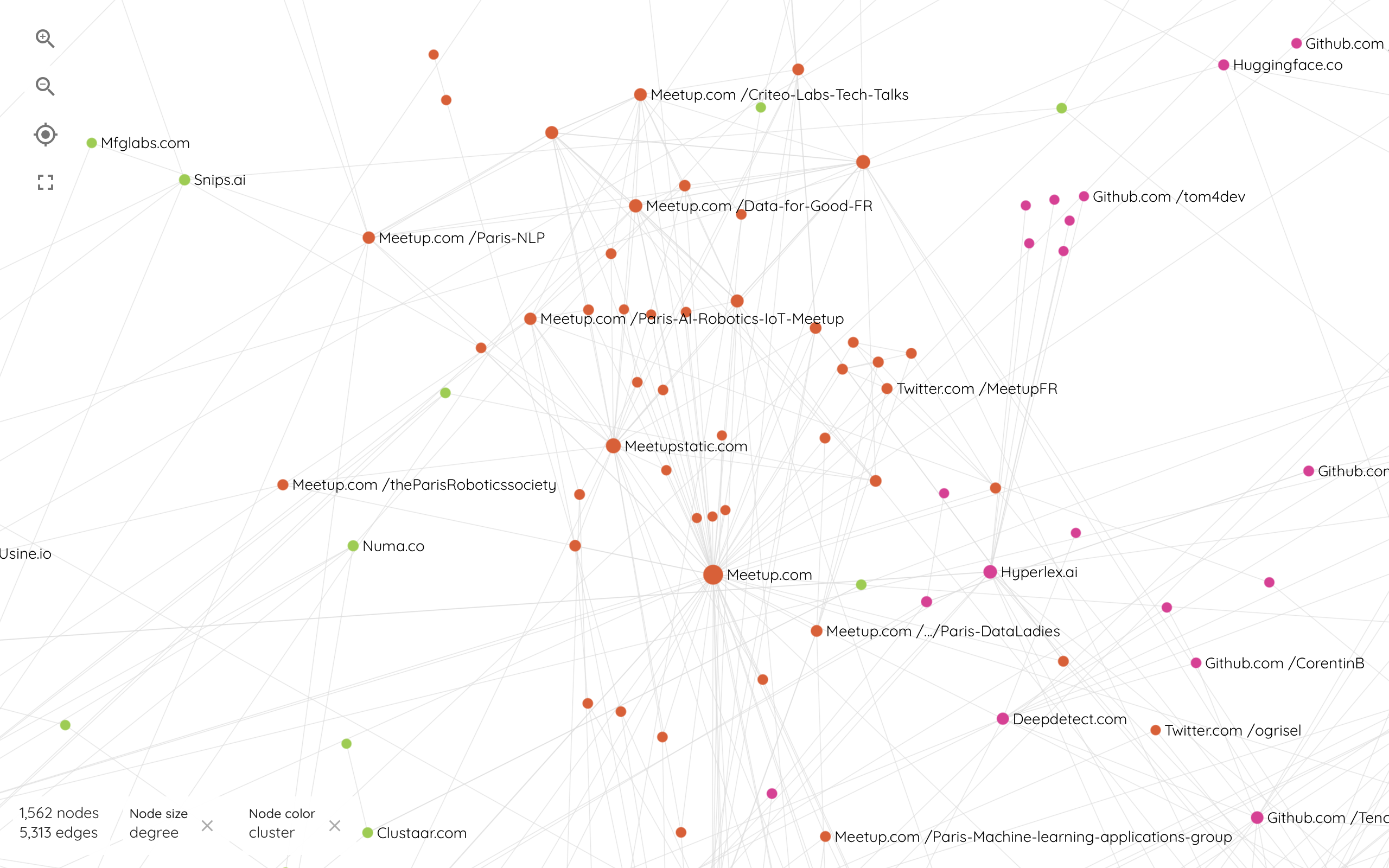
Les communautés de développeurs
Le plus petit cluster qui ne représente que 5,5% du réseau complet est composé de 48,8% d'entités étiquetées comme communautés, essentiellement des pages meetup d'organisation d'événements entre développeurs autour de territoires ou de problématiques différentes autour de l'IA. Cette petite sous-partie du réseau est la plus dense mais pas totalement homogène puisqu'elle est composée d'un quart de startups (25,6%) et de 16,3% de repository. Elle se connecte assez logiquement à l'intersection des composantes business et technique du graphe.
Méthodologie
Cette cartographie du web a été réalisée en en Septembre 2019 à partir de données extraites du Web au printemps 2019 à partir du logiciel de crawl Hyphe. Le corpus a été principalement constitué par quatre sites de départ (https://www.hub-franceia.fr ; https://franceisai.com/ ; https://cartographie-ia.enseignementsup-recherche.pro/acteurs.php# ; https://aiparis.fr/2019/) qui agrègent des listes d'acteurs français (recherche, startup) autour de l'IA dans divers domaines. A ces principaux sites ont été ajoutés 15 sites web (articles de presse, incubateurs, communauté de développeurs) recensant également des acteurs dans le domaine de l'intelligence artificielle.Ce corpus de départ a permis de récupérer une première série de web entités (Jacomy et al, 2016) en effectuant un crawl de profondeur n+1. De manière itérative un travail de nettoyage a consisté à crawler les nouvelles entités découvertes en lien avec la thématique (startup, incubateur, recherche, communauté) et à supprimer les entités non associées à la France, hors de la thématique concernée, les sites de presse et les sites inactifs. Afin de clôturer le crawl, il a été décidé de supprimer toutes les entités dont le degré (nombre de liens hypertextes) était inférieur à 3 avec le corpus constitué. Par conséquent, certains acteurs de l'IA ayant peu d'interconnexions sur le web ne figurent pas dans la cartographie. Un travail de catégorisation à la main de toutes les entités a été effectué avant d’identifier les types d'acteurs qui composent le réseau. Le graphe final visualisé à partir du logiciel d'exploration de réseaux Gephi est composé de 1562 entités web reliées entre elles par un ensemble de 5313 liens hypertextes. La taille de nœuds est relative au degré des entités web (le nombre de liens hypertextes qui les connecte au reste du graphe). Les couleurs sont relatives à la modularité qui détecte et catégorise automatiquement les sous-ensembles qui forment des zones plus denses dans le réseau. On observe 4 clusters principaux (modularité avec une résolution de 1.5 en aléatoire) de taille assez inégale, et dont la structure est assez stable (plusieurs itérations de l'algorithme de modularité), seul deux clusters d'environ une dizaine d'entités web ont été associés à un cluster proche plus important pour faciliter la lecture de l'ensemble.
NB : Ce réseau ne prétend pas être exhaustif, du fait de contraintes techniques liées aux outils de crawl ou du ciblage du sourcing certains acteurs de l'écosystème liés à l’intelligence artificielle peuvent ne pas y être présents. Par ailleurs, le terme d'intelligence artificielle est à prendre ici dans une acceptation large, tout acteur qui présente ou déclare avoir tout ou partie de ses activités liées à l'IA est ainsi considéré comme dans la thématique.
Annexes
Détail des catégories d’acteurs :
- research : école, université, projet ou laboratoire de recherche public et privé, logiciels techniques issus de la recherche, site de communication recherche
- institution : niveau Européen et national, ministères, collectivités territoriales, soutien au développement économique
- incubator : incubateurs territoriaux, incubateurs liés à des écoles ou privés
- startup : sociétés spécialisées mettant en avant une partie de leur activité en lien avec l’IA
- company : grands groupes et sociétés françaises ou internationales avec une activité en France (domaines variés : technologie, télécom, transport, énergie, santé, etc.)
- finance : banques, assureurs, fonds de capital risque
- community : page de groupes et de rencontre autour de l’IA meetup
- repository : pages github (personnes, équipe, projets, entreprise, recherche)
- event : colloque, , conférences, compétitions
Crédits
Pour toute demande d'accès aux données ou de collaboration au sujet de cette cartographie vous pouvez contacter l'équipe : contact@medialab.sciencespo.fr
Ce travail est issus d'un partenariat entre le médialab de Sciences Po et la Chaire Good in Tech.
Ce travail s’inscrit dans le cadre des travaux du projet ALGODIV (ANR-15-CE38-0001)